参考:算法模版 ,希望后续整理时给出c++、java、python版本的代码和算法思路。
排序算法都归纳到此处,不再另开文档记录。
排序方式 指是原地排序还是非原地排序。原地排序只使用常数级别的额外空间,而非原地排序需要额外的存储空间(通常与输入规模相关)。
稳定性 是指排序算法在排序后能够保持相等元素的相对顺序。换句话说,如果两个元素的值相等,排序后它们的相对位置与排序前相同。
排序算法
平均时间复杂度
最好情况
最坏情况
空间复杂度
排序方式
稳定性
冒泡排序
O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) In-place
稳定
选择排序
O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) In-place
不稳定
插入排序
O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) In-place
稳定
希尔排序
O ( n log n ) O(n\log n) O ( n log n ) O ( n log 2 n ) O(n\log^2 n) O ( n log 2 n ) O ( n log 2 n ) O(n\log^2 n) O ( n log 2 n ) O ( 1 ) O(1) O ( 1 ) In-place
不稳定
归并排序
O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n\log n) O ( n log n ) O ( n ) O(n) O ( n ) Out-place
稳定
快速排序
O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n\log n) O ( n log n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( log n ) O(\log n) O ( log n ) In-place
不稳定
堆排序
O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n\log n) O ( n log n ) O ( 1 ) O(1) O ( 1 ) In-place
不稳定
计数排序
O ( n + k ) O(n+k) O ( n + k ) O ( n + k ) O(n+k) O ( n + k ) O ( n + k ) O(n+k) O ( n + k ) O ( k ) O(k) O ( k ) Out-place
稳定
桶排序
O ( n + k ) O(n+k) O ( n + k ) O ( n + k ) O(n+k) O ( n + k ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n + k ) O(n+k) O ( n + k ) Out-place
稳定
基数排序
O ( n × k ) O(n\times k) O ( n × k ) O ( n × k ) O(n\times k) O ( n × k ) O ( n × k ) O(n\times k) O ( n × k ) O ( n + k ) O(n+k) O ( n + k ) Out-place
稳定
算法思路:基于 分治法 ,通过递归地将数组划分为较小的子数组来实现排序。
基准值(Pivot)的选择 :
代码中选择的基准值是数组中间的元素:x = q[l + r >> 1]。
l + r >> 1 等价于 (l + r) / 2,即取中间位置的值。
分区操作 :
使用两个指针 i 和 j,分别从数组的左右两端向中间移动。
i 从左向右找到第一个大于等于基准值的元素。j 从右向左找到第一个小于等于基准值的元素。如果 i 和 j 未相遇,则交换这两个元素,确保左边的元素小于等于基准值,右边的元素大于等于基准值。
递归排序 :
分区完成后,递归地对左半部分(l 到 j)和右半部分(j + 1 到 r)进行排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void quick_sort (int q[], int l, int r) if (l >= r) return ; int i = l - 1 , j = r + 1 , x = q[l + r >> 1 ]; while (i < j) { do i++; while (q[i] < x); do j--; while (q[j] > x); if (i < j) swap (q[i], q[j]); } quick_sort (q, l, j); quick_sort (q, j + 1 , r); }
ps. 归并排序有很多可讨论分析的点,比如逆序对。待补充...
算法思路:基于 分治法 ,将数组分成两个子数组,分别排序后再合并。
分治思想 :
将数组从中间分成两个子数组:[l, mid] 和 [mid + 1, r]。
递归地对两个子数组进行排序。
合并操作 :
使用两个指针 i 和 j,分别指向左子数组和右子数组的起始位置。
比较 q[i] 和 q[j],将较小的元素放入临时数组 tmp 中。
如果其中一个子数组的元素已经全部放入 tmp,则将另一个子数组的剩余元素直接放入 tmp。
临时数组的使用 :
tmp 是一个临时数组,用于存储合并后的有序结果。最后将 tmp 中的元素复制回原数组 q。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void merge_sort (int q[], int l, int r) if (l >= r) return ; int mid = l + r >> 1 ; merge_sort (q, l, mid); merge_sort (q, mid + 1 , r); int k = 0 , i = l, j = mid + 1 ; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k++] = q[i++]; else tmp[k++] = q[j++]; while (i <= mid) tmp[k++] = q[i++]; while (j <= r) tmp[k++] = q[j++]; for (i = l, j = 0 ; i <= r; i++, j++) q[i] = tmp[j]; }
完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <vector> using namespace std;int bsearch_left (const vector<int >& nums, int target) int l = 0 , r = nums.size () - 1 ; while (l < r) { int mid = l + r >> 1 ; if (nums[mid] >= target) r = mid; else l = mid + 1 ; } return l; } int bsearch_right (const vector<int >& nums, int target) int l = 0 , r = nums.size () - 1 ; while (l < r) { int mid = l + r + 1 >> 1 ; if (nums[mid] <= target) l = mid; else r = mid - 1 ; } return l; } int main () vector<int > nums = {1 , 2 , 2 , 3 , 4 }; int target = 2 ; int left = bsearch_left (nums, target); int right = bsearch_right (nums, target); cout << "第一个 >= " << target << " 的索引: " << left << endl; cout << "最后一个 <= " << target << " 的索引: " << right << endl; return 0 ; }
打印信息:
1 2 第一个 >= 2 的索引: 1 最后一个 <= 2 的索引: 2
bsearch_left第一个满足条件的值 (左边界),如 lower_bound。bsearch_right最后一个满足条件的值 (右边界),如 upper_bound - 1。关键点 :
mid 的计算方式不同(右边界需要 +1 防止死循环)。更新 l 和 r 的逻辑不同(左边界 r = mid,右边界 l = mid)。
这两个模板能覆盖绝大多数二分查找问题,只需根据问题调整 check(x) 的逻辑即可。
本质思路同整数二分,按我浅薄的理解,仅仅是终止条件变成了与目标差多少的接受范围。
适用场景 :[l, r] 中查找满足 check(x) 的浮点数 x,要求结果精度达到 eps(如 1e-6)。与整数二分的区别 :
不需要处理 ±1 的边界问题,直接缩小区间即可。原因是浮点数是连续的,区间可以无限细分,直接赋值 l = mid 或 r = mid 即可。
终止条件是区间长度小于精度 eps(而非 l < r)。
1 2 3 4 5 6 7 8 9 double bsearch (double l, double r) const double eps = 1e-6 ; while (r - l > eps) { double mid = (l + r) / 2 ; if (check (mid)) r = mid; else l = mid; } return l; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vector<int > add (vector<int > &A, vector<int > &B) if (A.size () < B.size ()) return add (B, A); vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size (); i++) { t += A[i]; if (i < B.size ()) t += B[i]; C.push_back (t % 10 ); t /= 10 ; } if (t) C.push_back (t); return C; }
数字存储方式 :
数字是逆序存储的(例如数字"123"存为[3,2,1]),这样便于处理进位
长度处理技巧 :
if (A.size() < B.size()) 确保A总是较长的数,避免重复判断
进位处理 :
变量t既用于累加当前位的和,又通过t /= 10保存进位
最后的if (t)处理最高位产生的进位(如999+1=1000的情况)
时间复杂度 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vector<int > sub (vector<int > &A, vector<int > &B) vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size (); i++) { t = A[i] - t; if (i < B.size ()) t -= B[i]; C.push_back ((t + 10 ) % 10 ); if (t < 0 ) t = 1 ; else t = 0 ; } while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C; }
数字存储方式
数字是逆序存储的(如 123 存为 [3, 2, 1]),便于逐位计算。
借位处理
t 表示当前位的临时结果和借位状态:
t = A[i] - t:先减去上一位的借位。t -= B[i]:再减去 B 的当前位(如果存在)。
(t + 10) % 10:t < 0,说明需要借位,(t + 10) 得到正确值(如 -3 + 10 = 7);t >= 0,(t + 10) % 10 不影响结果(如 7 % 10 = 7)。
借位标志更新
if (t < 0) t = 1:当前位计算后为负,标记需要向高位借位。else t = 0:无需借位。
去除前导零
逆序存储时,前导零在 vector 的末尾(如 [3, 0, 0] 表示 003 即 3)。
while (C.size() > 1 && C.back() == 0) 确保结果至少保留一位(避免 [] 表示 0)。
前提条件
必须保证 A >= B,否则结果会是补码形式(未处理负数情况)。
实现了 大数 A(逆序存储)与普通整数 b 的乘法运算 ,其中 A ≥ 0,b ≥ 0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vector<int > mul (vector<int > &A, int b) vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size () || t; i++) { if (i < A.size ()) t += A[i] * b; C.push_back (t % 10 ); t /= 10 ; } while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C; }
数字存储方式
大数 A 是逆序存储的(如 123 存为 [3, 2, 1]),便于逐位计算。
乘法与进位处理
t += A[i] \* bt 中。t % 10t /= 10
循环条件 i < A.size() || t
即使 A 的位数已遍历完(i >= A.size()),如果仍有进位 t != 0,则需要继续处理(如 999*9=8991,最后进位 8 需单独处理)。
去除前导零
逆序存储时,前导零在 vector 的末尾(如 [0, 0, 0] 表示 000 即 0)。
while (C.size() > 1 && C.back() == 0) 确保结果至少保留一位(避免 [] 表示 0)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vector<int > div (vector<int > &A, int b, int &r) { vector<int > C; r = 0 ; for (int i = A.size () - 1 ; i >= 0 ; i--) { r = r * 10 + A[i]; C.push_back (r / b); r %= b; } reverse (C.begin (), C.end ()); while (C.size () > 1 && C.back () == 0 ) { C.pop_back (); } return C; }
输入 :
A:大数的逆序存储 (低位在前,比如数字123,A = [3, 2, 1])。b:除数(b > 0)。
输出 :
C:商的逆序存储(但最后会反转回高位在前)。r:余数(0 ≤ r < b)。
核心步骤
初始化 :
逐位计算 :
从高位到低位 (因A是逆序存储,所以i从A.size()-1递减到0):
当前位的被除数 = r * 10 + A[i](模拟手工除法的“落位”操作)。
将商(当前被除数 / b)存入C。
更新余数r = 当前被除数 % b。
后处理 :
反转C :因为计算时是按高位到低位顺序存入,但实际需要低位在前存储,所以反转。去除前导零 :比如商是0123,需清理为123(保留至少一个0)。
KMP 是一个解决模式串在文本串是否出现过,如果出现过,最早出现的位置的经典算法。
关于字符串匹配,如果有两个字符串,其中一个较短的叫它子串(长度为n),较长的叫他主串(长度为m),那么该怎样确定子串在主串中的位置呢?O ( m n ) O(mn) O ( m n ) O ( m + n ) O(m+n) O ( m + n )
当发现某一个字符不匹配时,已经知道之前遍历过的字符,怎样利用已知信息避免暴力算法中的“回退”步骤呢?
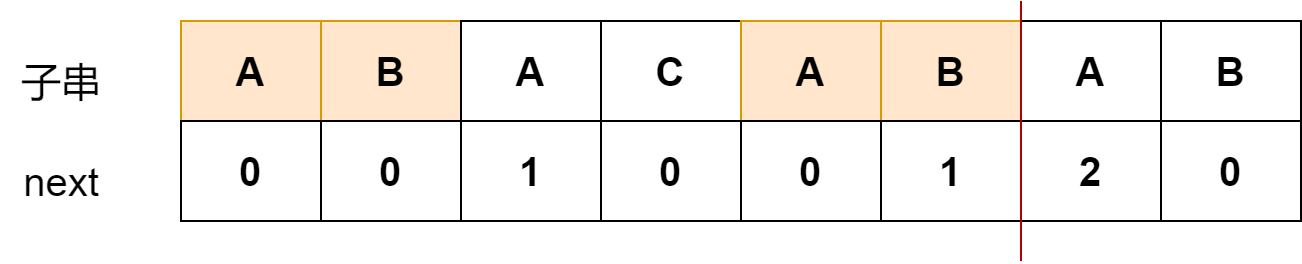
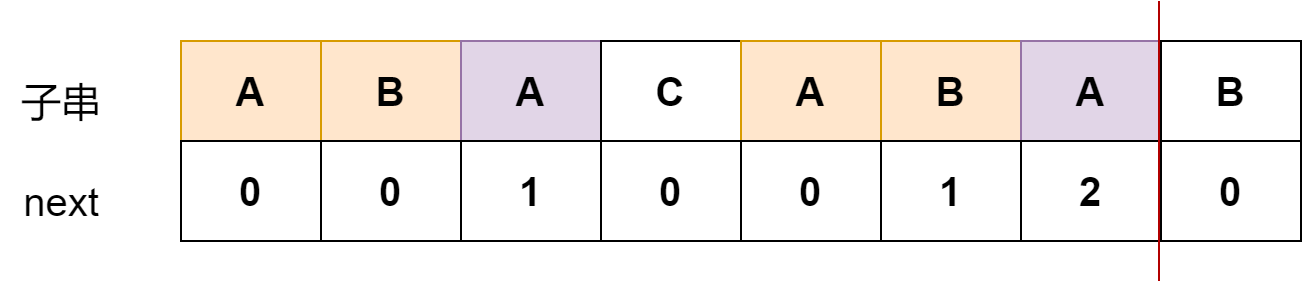
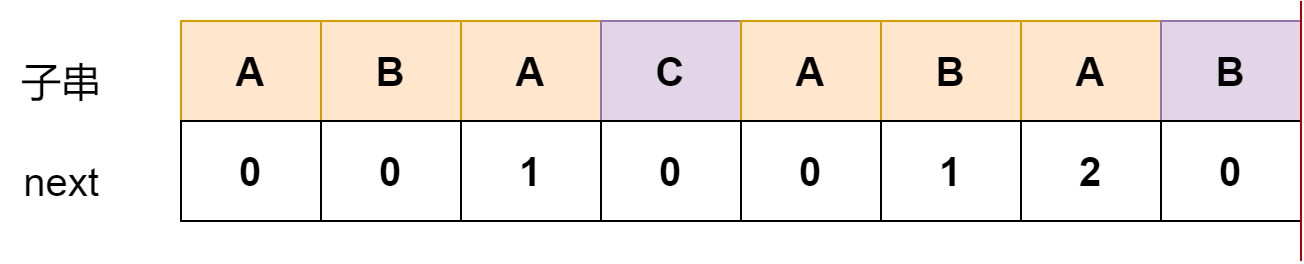
求解过程如下:
当前共同前后缀是2
如果下一个字符依然相同,那么下一个共同前后缀的长度就是2+1=3
如果下一个字符不相同,即ABA无法与下一个字符构成更长的前后缀,
cur_length = 1, B可以匹配,所以B这里的next值为2
匹配两次才能成功的一个例子:aacaabaacaaa,最后一位需要匹配两次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def getNext (s ): ans = [0 ] cur_len = 0 i = 1 while i < len (s): if s[cur_len] == s[i]: cur_len += 1 ans.append(cur_len) i += 1 else : if cur_len == 0 : ans.append(0 ) i += 1 else : cur_len = ans[cur_len - 1 ] return ans def KMP_search (s, patt ): pos = getNext(patt) i, j = 0 , 0 while i < len (s): if s[i] == patt[j]: i += 1 j += 1 elif j > 0 : j = pos[j - 1 ] else : i += 1 if j == len (patt): return i - j
并查集(Union-Find Data Structure),也被称为不相交集(Disjoint Sets/Disjoint Set Union, DSU)或合并-查找集,是一种高效的数据结构,主要用于处理一些不相交集合(即集合之间没有交集)的合并及查询问题。在计算机科学中,并查集常用于解决图的连通性问题,如判断图中的两个节点是否属于同一个连通分量,或者判断一个无向图是否是连通图等。
并查集的基本思想是将元素分组,每组的元素之间具有某种关系(如连通性),并且这种关系具有传递性。算法通过维护一个父节点数组(或其他类似的数据结构)来实现元素的分组。初始时,每个元素自成一个集合,即每个元素的父节点指向自己。在合并两个集合时,通过修改父节点数组,将其中一个集合的根节点的父节点指向另一个集合的根节点,从而实现两个集合的合并。在查询两个元素是否属于同一个集合时,可以通过查找它们的根节点是否相同来判断。
并查集主要包含以下几个基本操作:
初始化(Make-Set):为每个元素创建一个只包含自身的集合。
查找(Find):确定一个元素所属的集合,即找到该元素的根节点。查找操作通常伴随着“路径压缩”优化,即将沿途经过的所有节点直接连接到它们的根节点,从而加速后续的查找操作。
合并(Union):将两个不同的集合合并成一个集合。合并时,通常采用按秩(每个集合中树的最大深度)或按大小(集合中元素的数量)的启发式合并策略,以避免树的高度过高,保证操作的近似对数时间复杂度。
并查集的实现方式多种多样,但核心思想都是通过维护一个父节点数组来记录元素的分组情况。以下是一种常见的实现方式:
使用一个数组parent来表示每个元素的父节点。初始时,parent[i] = i,表示每个元素自成一个集合。
使用一个数组parent来表示每个元素的父节点。初始时,parent[i] = i,表示每个元素自成一个集合。
时间复杂度:
初始化:O(n)
find和union操作:接近O(1)(阿克曼函数的反函数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class DSU : def __init__ (self, size ): """初始化并查集,size为元素个数""" self .parent = list (range (size)) self .rank = [0 ] * size def find (self, x ): """查找元素x的根节点,带路径压缩优化""" if self .parent[x] != x: self .parent[x] = self .find(self .parent[x]) return self .parent[x] def union (self, x, y ): """合并元素x和y所在的集合,按秩合并优化""" x_root = self .find(x) y_root = self .find(y) if x_root == y_root: return if self .rank[x_root] < self .rank[y_root]: self .parent[x_root] = y_root else : self .parent[y_root] = x_root if self .rank[x_root] == self .rank[y_root]: self .rank[x_root] += 1 def is_connected (self, x, y ): """检查x和y是否在同一集合""" return self .find(x) == self .find(y)
LCS 03. 主题空间 - 力扣(LeetCode)
1971. 寻找图中是否存在路径 - 力扣(LeetCode)
128. 最长连续序列 - 力扣(LeetCode)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 vector, 变长数组,倍增的思想 size () 返回元素个数 empty () 返回是否为空 clear () 清空 front ()/back () push_back ()/pop_back () begin ()/end () [] 支持比较运算,按字典序 pair first, 第一个元素 second, 第二个元素 支持比较运算,以first为第一关键字,以second为第二关键字(字典序) string,字符串 size ()/length () 返回字符串长度 empty () clear () substr (起始下标,(子串长度)) 返回子串 c_str () 返回字符串所在字符数组的起始地址 queue, 队列 size () empty () push () 向队尾插入一个元素 front () 返回队头元素 back () 返回队尾元素 pop () 弹出队头元素 priority_queue, 优先队列,默认是大根堆 size () empty () push () 插入一个元素 top () 返回堆顶元素 pop () 弹出堆顶元素 定义成小根堆的方式:priority_queue, greater> q; stack, 栈 size () empty () push () 向栈顶插入一个元素 top () 返回栈顶元素 pop () 弹出栈顶元素 deque, 双端队列 size () empty () clear () front ()/back () push_back ()/pop_back () push_front ()/pop_front () begin ()/end () [] set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列 size () empty () clear () begin ()/end () ++, -- 返回前驱和后继,时间复杂度 O (logn) set/multiset insert () 插入一个数 find () 查找一个数 count () 返回某一个数的个数 erase () (1 ) 输入是一个数x,删除所有x O (k + logn) (2 ) 输入一个迭代器,删除这个迭代器 lower_bound () /upper_bound () lower_bound (x) 返回大于等于x的最小的数的迭代器 upper_bound (x) 返回大于x的最小的数的迭代器 map/multimap insert () 插入的数是一个pair erase () 输入的参数是pair或者迭代器 find () [] 注意multimap不支持此操作。 时间复杂度是 O (logn) lower_bound () /upper_bound () unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表 和上面类似,增删改查的时间复杂度是 O (1 ) 不支持 lower_bound () /upper_bound () , 迭代器的++,-- bitset, 圧位 bitset<10000> s ; ~, &, |, ^ >>, << ==, != [] count () 返回有多少个1 any () 判断是否至少有一个1 none () 判断是否全为0 set () 把所有位置成1 set (k, v) 将第k位变成v reset () 把所有位变成0 flip () 等价于~ flip (k) 把第k位取反
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import java.util.*;List<Integer> list = new ArrayList <>(); list.size(); list.isEmpty(); list.clear(); list.get(0 ); list.add(1 ); list.remove(list.size() - 1 ); LinkedList<Integer> deque = new LinkedList <>(); deque.addFirst(1 ); deque.addLast(2 ); deque.removeFirst(); deque.removeLast(); PriorityQueue<Integer> pq = new PriorityQueue <>(); pq = new PriorityQueue <>(Collections.reverseOrder()); pq.size(); pq.isEmpty(); pq.add(1 ); pq.peek(); pq.poll(); Stack<Integer> stack = new Stack <>(); stack.size(); stack.isEmpty(); stack.push(1 ); stack.peek(); stack.pop(); Set<Integer> set = new HashSet <>(); set.add(1 ); set.contains(1 ); set.remove(1 ); Map<String, Integer> map = new HashMap <>(); map.put("key" , 1 ); map.get("key" ); map.remove("key" ); TreeSet<Integer> treeSet = new TreeSet <>(); treeSet.add(1 ); treeSet.contains(1 ); treeSet.remove(1 ); treeSet.lower(1 ); treeSet.higher(1 ); TreeMap<String, Integer> treeMap = new TreeMap <>(); treeMap.put("key" , 1 ); treeMap.get("key" ); treeMap.remove("key" ); treeMap.lowerKey("key" ); treeMap.higherKey("key" );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from collections import deque, defaultdictimport heapqlst = [] len (lst) not lst lst.clear() lst[0 ] lst.append(1 ) lst.pop() dq = deque() dq.appendleft(1 ) dq.append(2 ) dq.popleft() dq.pop() heapq.heapify(lst) heapq.heappush(lst, 1 ) heapq.heappop(lst) lst[0 ] s = set () s.add(1 ) 1 in s s.remove(1 ) d = {} d["key" ] = 1 d["key" ] del d["key" ] dd = defaultdict(int ) dd["key" ] += 1 from sortedcontainers import SortedSet, SortedDictss = SortedSet() ss.add(1 ) 1 in ss ss.discard(1 ) ss.bisect_left(1 ) ss.bisect_right(1 ) sd = SortedDict() sd["key" ] = 1 sd["key" ] del sd["key" ] sd.bisect_left("key" ) sd.bisect_right("key" )